AI-in-the-loop Workflow
This is an example of how Dragon can be used to execute an AI-in-the-loop workflow. Inspiration for this demo comes from the NERSC-10 Workflow Archetypes White Paper. This workflow most closely resembles the workflow scenario given as part of archetype four.
In this example, we use a small model implemented in PyTorch to compute an approximation to \(\sin(x)\).
In parallel, while performing inference with the model, we launch sim-cheap on four MPI ranks.
This MPI job computes the Taylor approximation to \(\sin(x)\) and compares this with the output of the model.
If the difference is less than 0.05 we consider the model’s approximation to be sufficiently accurate and print out the
result with the exact result.
If the difference is greater than 0.05 we consider this a failure and re-train the model on a new set of data.
To generate this data we launch sim-expensive.
This MPI job is launched on eight ranks-per-node and each rank generates 32 data points of the form \((x, \sin(x))\)
where \(x \in U(-\pi, \pi)\).
This data is aggregated into a PyTorch tensor and then used to train the model.
We then re-evaluate the re-trained model and decide if we need to re-train again or if the estimate is sufficiently
accurate. We continue this loop until we’ve had five successes.
Fig. 7 presents the structure of this main loop. It shows when each MPI application is launched and what portions are executed in parallel.
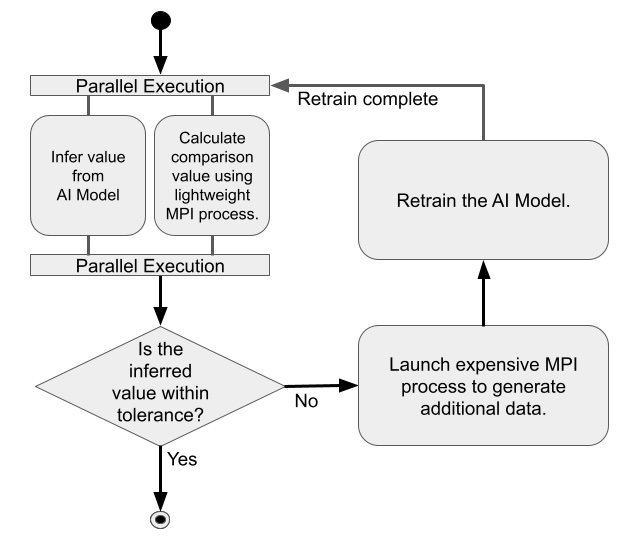
Fig. 7 Example AI-in-the-loop workflow
This example consists of the following python files:
ai-in-the-loop.py- This is the main file. It contains functions for launching both MPI executables and parsing the results as well as imports functions defined inmodel.pyand coordinates the model inference and training with the MPI jobs.model.py- This file defines the model and provides some functions for model training and inference.
Below, we present the main Python code ai-in-the-loop.py , which acts as the coordinator of the workflow. The code of the other files can be found in ai-in-the-loop .
1import dragon
2import multiprocessing as mp
3
4import os
5import math
6import torch
7from itertools import count
8from model import Net, make_features, infer, train
9
10from dragon.native.process import Process, ProcessTemplate, Popen
11from dragon.native.process_group import ProcessGroup
12from dragon.infrastructure.connection import Connection
13from dragon.infrastructure.facts import PMIBackend
14from dragon.native.machine import System
15
16
17def parse_results(stdout_conn: Connection) -> tuple:
18 """Read stdout from the Dragon connection.
19
20 :param stdout_conn: Dragon connection to rank 0's stdout
21 :type stdout_conn: Connection
22 :return: tuple with a list of x values and the corresponding sin(x) values.
23 :rtype: tuple
24 """
25 x = []
26 y = []
27 output = ""
28 try:
29 # this is brute force
30 while True:
31 output += stdout_conn.recv()
32 except EOFError:
33 pass
34 finally:
35 stdout_conn.close()
36
37 split_line = output.split("\n")
38 for line in split_line[:-1]:
39 try:
40 x_val = float(line.split(",")[0])
41 y_val = float(line.split(",")[1])
42 x.append(x_val)
43 y.append(y_val)
44 except (IndexError, ValueError):
45 pass
46
47 return x, y
48
49
50def generate_data(num_ranks: int, samples_per_rank: int, sample_range: list, number_of_times_trained: int) -> tuple:
51 """Launches mpi application that generates (x, sin(x)) pairs uniformly sampled from [sample_range[0], sample_range[1]).
52
53 :param num_ranks: number of ranks to use to generate data
54 :type num_ranks: int
55 :param samples_per_rank: number of samples to generate per rank
56 :type samples_per_rank: int
57 :param sample_range: range from which to sample training data
58 :type sample_range: list
59 :param number_of_times_trained: number of times trained. can be used to set a seed for the mpi application.
60 :type number_of_times_trained: int
61 :return: tuple of PyTorch tensors containing data and targets respectively
62 :rtype: tuple
63 """
64 """Launch process group and parse data"""
65 exe = os.path.join(os.getcwd(), "sim-expensive")
66 args = [str(samples_per_rank), str(sample_range[0]), str(sample_range[1]), str(number_of_times_trained)]
67 run_dir = os.getcwd()
68
69 grp = ProcessGroup(restart=False, pmi=PMIBackend.CRAY)
70
71 # Pipe the stdout output from the head process to a Dragon connection
72 grp.add_process(nproc=1, template=ProcessTemplate(target=exe, args=args, cwd=run_dir, stdout=Popen.PIPE))
73
74 # All other ranks should have their output go to DEVNULL
75 grp.add_process(
76 nproc=num_ranks - 1, template=ProcessTemplate(target=exe, args=args, cwd=run_dir, stdout=Popen.DEVNULL)
77 )
78 # start the process group
79 grp.init()
80 grp.start()
81 group_procs = [Process(None, ident=puid) for puid in grp.puids]
82 for proc in group_procs:
83 if proc.stdout_conn:
84 # get info printed to stdout from rank 0
85 x, y = parse_results(proc.stdout_conn)
86 # wait for workers to finish and shutdown process group
87 grp.join()
88 grp.stop()
89 grp.close()
90 # transform data into tensors for training
91 data = torch.tensor(x)
92 target = torch.tensor(y)
93 return data, target.unsqueeze(1)
94
95
96def compute_cheap_approx(num_ranks: int, x: float) -> float:
97 """Launch process group with cheap approximation and parse output to float as a string
98
99 :param num_ranks: number of mpi ranks (and therefor terms) to use for the cheap approximation
100 :type num_ranks: int
101 :param x: point where you are trying to compute sin(x)
102 :type x: float
103 :return: taylor expansion of sin(x)
104 :rtype: float
105 """
106 exe = os.path.join(os.getcwd(), "sim-cheap")
107 args = [str(x)]
108 run_dir = os.getcwd()
109
110 grp = ProcessGroup(restart=False, pmi=PMIBackend.CRAY)
111
112 # Pipe the stdout output from the head process to a Dragon connection
113 grp.add_process(nproc=1, template=ProcessTemplate(target=exe, args=args, cwd=run_dir, stdout=Popen.PIPE))
114
115 # All other ranks should have their output go to DEVNULL
116 grp.add_process(
117 nproc=num_ranks - 1, template=ProcessTemplate(target=exe, args=args, cwd=run_dir, stdout=Popen.DEVNULL)
118 )
119 # start the process group
120 grp.init()
121 grp.start()
122 group_procs = [Process(None, ident=puid) for puid in grp.puids]
123 for proc in group_procs:
124 # get info printed to stdout from rank 0
125 if proc.stdout_conn:
126 _, y = parse_results(proc.stdout_conn)
127 # wait for workers to finish and shutdown process group
128 grp.join()
129 grp.stop()
130 grp.close()
131
132 return y
133
134
135def infer_and_compare(model: torch.nn, x: float) -> tuple:
136 """Launch inference and cheap approximation and check the difference between them
137
138 :param model: PyTorch model that approximates sin(x)
139 :type model: torch.nn
140 :param x: value where we want to evaluate sin(x)
141 :type x: float
142 :return: the model's output val and the difference between it and the cheap approximation value
143 :rtype: tuple
144 """
145 with torch.no_grad():
146 # queues to send data to and from inference process
147 q_in = mp.Queue()
148 q_out = mp.Queue()
149 q_in.put((model, x))
150 inf_proc = mp.Process(target=infer, args=(q_in, q_out))
151 inf_proc.start()
152 # launch mpi application to compute cheap approximation
153 te_fx = compute_cheap_approx(4, x.numpy()[0])
154 inf_proc.join()
155 model_val = q_out.get()
156 # compare cheap approximation and model value
157 diff = abs(model_val.numpy() - te_fx[0])
158
159 return model_val, diff
160
161
162def main():
163 ranks_per_node = 8
164 data_interval = [-math.pi, math.pi]
165 samples_per_rank = 32
166 my_alloc = System()
167 # Define model
168 model = Net()
169 # Define optimizer
170 optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
171 # Load pretrained model
172 PATH = "model_pretrained_poly.pt"
173 checkpoint = torch.load(PATH)
174 model.load_state_dict(checkpoint["model_state_dict"])
175 optimizer.load_state_dict(checkpoint["optimizer_state_dict"])
176
177 number_of_times_trained = 0
178 successes = 0
179
180 generate_new_x = True
181
182 while successes < 5:
183 if generate_new_x:
184 # uniformly sample from [-pi, pi)
185 x = torch.rand(1) * (2 * math.pi) - math.pi
186
187 model_val, diff = infer_and_compare(model, x)
188 if diff > 0.05:
189 print(f"training", flush=True)
190 # want to train and then retry same value
191 generate_new_x = False
192 number_of_times_trained += 1
193 # interval we uniformly sample training data from
194 # launch mpi job to generate data
195 data, target = generate_data(
196 my_alloc.nnodes * ranks_per_node, samples_per_rank, data_interval, number_of_times_trained
197 )
198 # train model
199 loss = train(model, optimizer, data, target)
200 else:
201 successes += 1
202 generate_new_x = True
203 print(f" approx = {model_val}, exact = {math.sin(x)}", flush=True)
204
205
206if __name__ == "__main__":
207 mp.set_start_method("dragon")
208 main()
Installation
After installing dragon, the only other dependency is on PyTorch. The PyTorch version and corresponding pip command can be found here (https://pytorch.org/get-started/locally/ ).
pip install torch torchvision torchaudio
Description of the system used
For this example, HPE Cray Hotlum nodes were used. Each node has AMD EPYC 7763 64-core CPUs.
How to run
Example Output when run on 16 nodes with 8 MPI ranks-per-node used to generate data and four MPI ranks to compute the cheap approximation
1> make
2gcc -g -pedantic -Wall -I /opt/cray/pe/mpich/8.1.26/ofi/gnu/9.1/include -L /opt/cray/pe/mpich/8.1.26/ofi/gnu/9.1/lib -c -o sim-cheap.o sim-cheap.c
3gcc -g -pedantic -Wall -I /opt/cray/pe/mpich/8.1.26/ofi/gnu/9.1/include -L /opt/cray/pe/mpich/8.1.26/ofi/gnu/9.1/lib sim-cheap.o -o sim-cheap -lm -L /opt/cray/pe/mpich/8.1.26/ofi/gnu/9.1/lib -lmpich
4gcc -g -pedantic -Wall -I /opt/cray/pe/mpich/8.1.26/ofi/gnu/9.1/include -L /opt/cray/pe/mpich/8.1.26/ofi/gnu/9.1/lib -c -o sim-expensive.o
5gcc -g -pedantic -Wall -I /opt/cray/pe/mpich/8.1.26/ofi/gnu/9.1/include -L /opt/cray/pe/mpich/8.1.26/ofi/gnu/9.1/lib sim-expensive.o -o sim-expensive -lm -L /opt/cray/pe/mpich/8.1.26/ofi/gnu/9.1/lib -lmpich
6> salloc --nodes=16 --exclusive
7> dragon ai-in-the-loop.py
8training
9approx = 0.1283823400735855, exact = 0.15357911534767393
10training
11approx = -0.41591891646385193, exact = -0.4533079140996079
12approx = -0.9724616408348083, exact = -0.9808886564963794
13approx = -0.38959139585494995, exact = -0.4315753703483373
14approx = 0.8678910732269287, exact = 0.8812041533601648