Creating and Using a Pipeline with Multiprocessing
With DragonHPC it is easy to distribute computation over a collection of nodes and cores. In addition, it can be distributed dynamically. Consider a prime number sieve, the Sieve of Eratosthenes. This example demonstrates building a pipeline on-the-fly while getting results from it as they become available.
The complete code for this example is provided in examples/multiprocessing/prime_numbers.py.
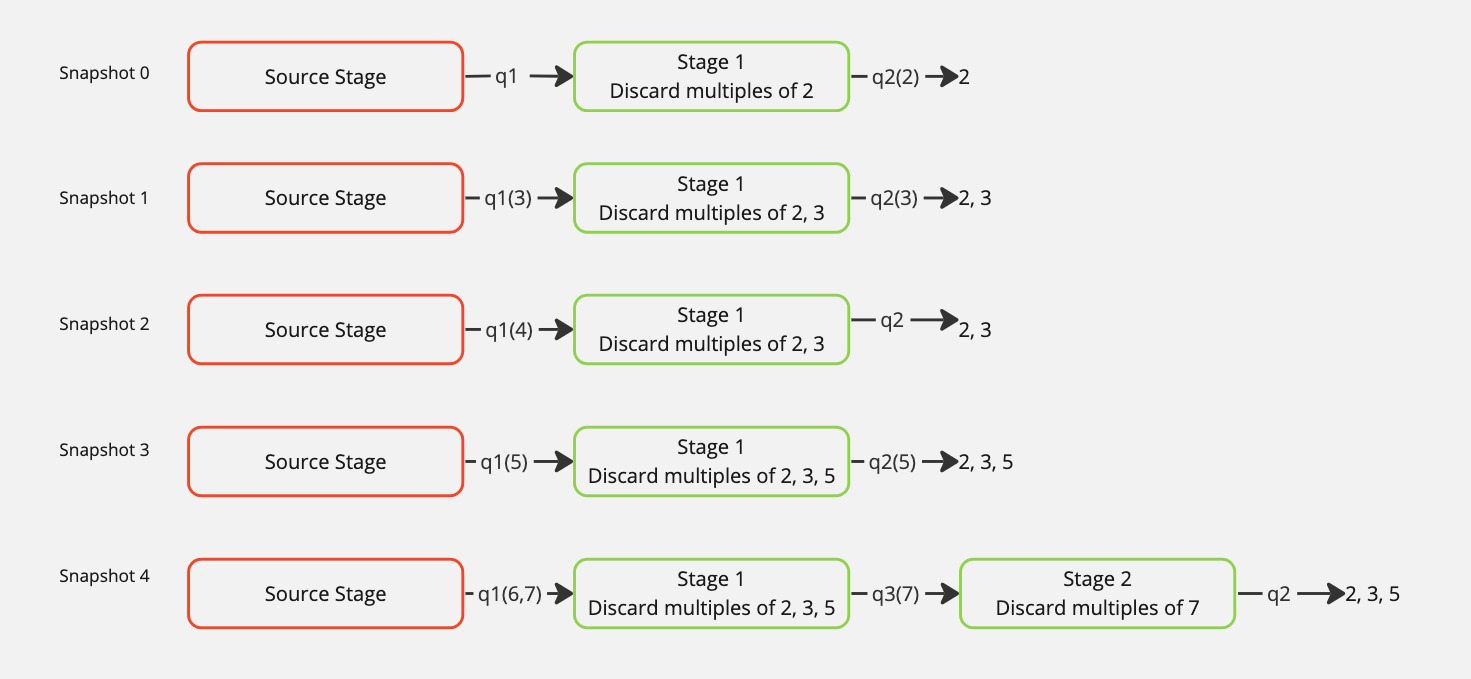
Fig. 5 Dynamic Growth of Prime Number Pipeline
Consider the code in Listing 8. Snapshot 0 in Fig. 5 depicts the state of the program just after startup. The main function creates a PrimeNumberPipeline object and calls start which creates two queues and two processes. The source process generates all numbers to be consider for primeness. The pipeline stage process receives integers from its input queue and forwards them on if they are relatively prime to the primes held in that stage.
Initially (i.e. in snapshot 0) the output from the stage goes directly to the sink queue where the user’s program will be receiving the prime numbers that made it through the sieve, in this case the main program.
Notice that in the code there is nothing that specifies where these processes are run. They could be run on any node. They could all be run on the same node. The program is not written any different either way, unless the programmer really wants to have more control over placement of these processes.
1class PrimeNumberPipeline:
2
3 ...
4
5 def start(self):
6 self._source_queue = mp.Queue(maxsize=PrimeNumberPipeline.MAX_QUEUE_DEPTH)
7 self._sink_queue = mp.Queue(maxsize=PrimeNumberPipeline.MAX_QUEUE_DEPTH)
8 self._source_proc = mp.Process(target=PrimeNumberPipeline.source, args=(self._max_number, self._source_queue))
9 self._source_proc.start()
10 self._sink_queue.put(2) # "Prime" the sink queue ;)
11 self._stage_proc = mp.Process(target=PrimeNumberPipeline.pipeline_stage, args=(self._stage_size, 2, self._source_queue, self._sink_queue))
12 self._stage_proc.start()
13
14 def stop(self):
15 self._source_proc.join()
16 self._stage_proc.join()
17
18 def get(self):
19 return self._sink_queue.get()
20
21
22def main():
23 # We set the start method to dragon to use dragon multiprocessing.
24 mp.set_start_method('dragon')
25
26 # We can control the pipeline by max_number and stage_size. The
27 # stage_size can control the amount of parallelism.
28 prime_pipeline = PrimeNumberPipeline(stage_size=3, max_number=100)
29 prime_pipeline.start()
30 print('Prime numbers:')
31 count = 0
32 for prime in iter(prime_pipeline.get, PrimeNumberPipeline.SENTINEL):
33 text = f'{prime} '
34 print(text, end="", flush=True)
35 count+= len(text)
36 if count > 80:
37 count = 0
38 print(flush=True)
39 print(flush=True)
40 prime_pipeline.stop()
41
42if __name__ == "__main__":
43 main()
Taking a look at the pipeline_stage code in Listing 9 the code is given a prime number when started to add to its list of primes. The stage will check that a number received from the input queue to the stage is relatively prime to the list of primes for the stage. If the new number is found to be relatively prime it is added to the list of primes for that stage if the list has not grown too large. In this way, each process in the pipeline can do a certain amount of sequential work which is tunable, depending on performance of the application.
When a stage has reached the capacity of the primes list, then a new stage is started as shown in snapshot 4. The new stage is passed a number that is the first prime greater than the primes in the previous stage. Lines 36-41 of Listing 9 is the code that recognizes a new stage is needed, creates it, and splices it into the pipeline. Notice that the way the new pipeline stage is spliced in, the original output queue remains the final output queue. In other words the writing end of that queue is passed from one process to another. It is that simple with multiprocessing and DragonHPC to pass around queues. You can pass queues around and they are managed accordingly. This might mean passing the queue on to a process that is on a completely different node. There is a lot of very subtle power in the DragonHPC implementation of multiprocessing.
1class PrimeNumberPipeline:
2
3 @staticmethod
4 def pipeline_stage(stage_size, prime, in_queue, out_queue):
5 # A stage is given a prime from which to start. All other
6 # primes it finds (up to the stage size) are added to this
7 # list of primes to check.
8 primes = [prime]
9 stage_proc = None
10
11 # This is the number of primes (relative to primes) that this
12 # stage has found.
13 cur_count = 1
14
15 while True:
16 number = in_queue.get()
17
18 # We terminate via a sentinel value.
19 if number == PrimeNumberPipeline.SENTINEL:
20 out_queue.put(PrimeNumberPipeline.SENTINEL)
21 if stage_proc is not None:
22 stage_proc.join()
23 print(f'\nprimes in pipeline stage are {primes}', flush=True)
24 return
25
26 if PrimeNumberPipeline.is_relatively_prime(number, primes):
27 # It is relatively prime, so send it to the output queue
28 out_queue.put(number)
29
30 # If it is found to be relatively prime, we add it to the
31 # list of primes or we create a new stage with it (which
32 # in turn builds its list of primes).
33 if cur_count < stage_size:
34 primes.append(number)
35
36 elif cur_count == stage_size:
37 # create a new pipeline stage
38 new_stage_queue = mp.Queue(maxsize=PrimeNumberPipeline.MAX_QUEUE_DEPTH)
39 stage_proc = mp.Process(target=PrimeNumberPipeline.pipeline_stage, args=(stage_size, number, new_stage_queue, out_queue))
40 out_queue = new_stage_queue
41 stage_proc.start()
42 else:
43 # It was checked/will be checked by other stages in the pipeline
44 pass
45
46 # Number of relatively prime primes found for this stage.
47 cur_count+=1
Of course as we progress through the sequence of prime numbers the pipeline grows. So this application will scale to a large number of prime numbers, but what is really amazing is that the same program will execute on your laptop, just not with the same performance as a supercomputer.
The other subtlety in this program is that no stage is going to get too far ahead in its processing. The MAX_QUEUE_DEPTH constant sets the allowable size of the queue. No stage will get further ahead than MAX_QUEUE_DEPTH because the put (line 28) and get (line 16) operations apply backpressure to processes. The put and get operations will block and therefore suspend a pipeline stage that gets to far ahead of its neighbors.
In the end this program demonstrates the dynamic nature of DragonHPC and its ability to dynamically construct workflows and re-route data at run-time. It also demonstrates the location independence of synchronization and communication objects in multiprocessing. Finally, it demonstrates the implicit flow control that is possible within these workflows which is managed by the ability of DragonHPC to apply backpressure on processes.