The Dragon HPC Resource Model
Programming for multi-system and/or cloud-like infrastructure will either be explicit or transparent. Explicit programming means writing provider-specific code (e.g., AWS API, Azure API, workload manager scripts for HPC). Each of these can be considered as having a resource model. The resources are typically physical hardware, such as nodes, and users are limited in the abstractions that can exist over the resources. The Dragon HPC Resource Model enables transparent programming over physical resources through logical resource abstractions. At the same time, users have access to information about the physical placement of logical resources and optional control over the policy of logical resources, including placement. With a transparent programming model, users can write sophisticated applications and workflows once and have them port across laptops, cloud, supercomputers, and federated multi-system environments.
Dragon implements a resource model inspired by Python Multiprocessing, which has abstractions proven to be productive for users writing applications and workflows. The Dragon HPC Resource Model takes these concepts and makes them accessible across programming languages so that processes of all types that may make up a workflow can all directly interact through the objects in the resource model.
All objects in the Dragon HPC Resource Model (the Dragon Native API) exist to one of two modes within the run-time: managed and unmanaged. Most users will write applications and workflows with managed objects, allowing the Dragon run-time to control the burden of life-cycle management of the objects and provide discoverability.
The Dragon run-time itself, and some use cases, require lower-level control of the objects in order to instantiate the objects into node-local memory. These cases will use unmanaged objects.
Once instantiated, objects can be shared once a process has a valid handle to it. We call this handle a Serialized Descriptor, it can be passed between processes via stdin, sockets, pipes or any other form of communication to enable two processes to use the same object. As this can become cumbersome to program, managed objects can be further identified by their user defined name or run-time defined unique ID. Both are held by the Dragon run-time services, and if an object is created a second time with the same name, the run-time will instead return the existing object to the process.
Object Hierarchy
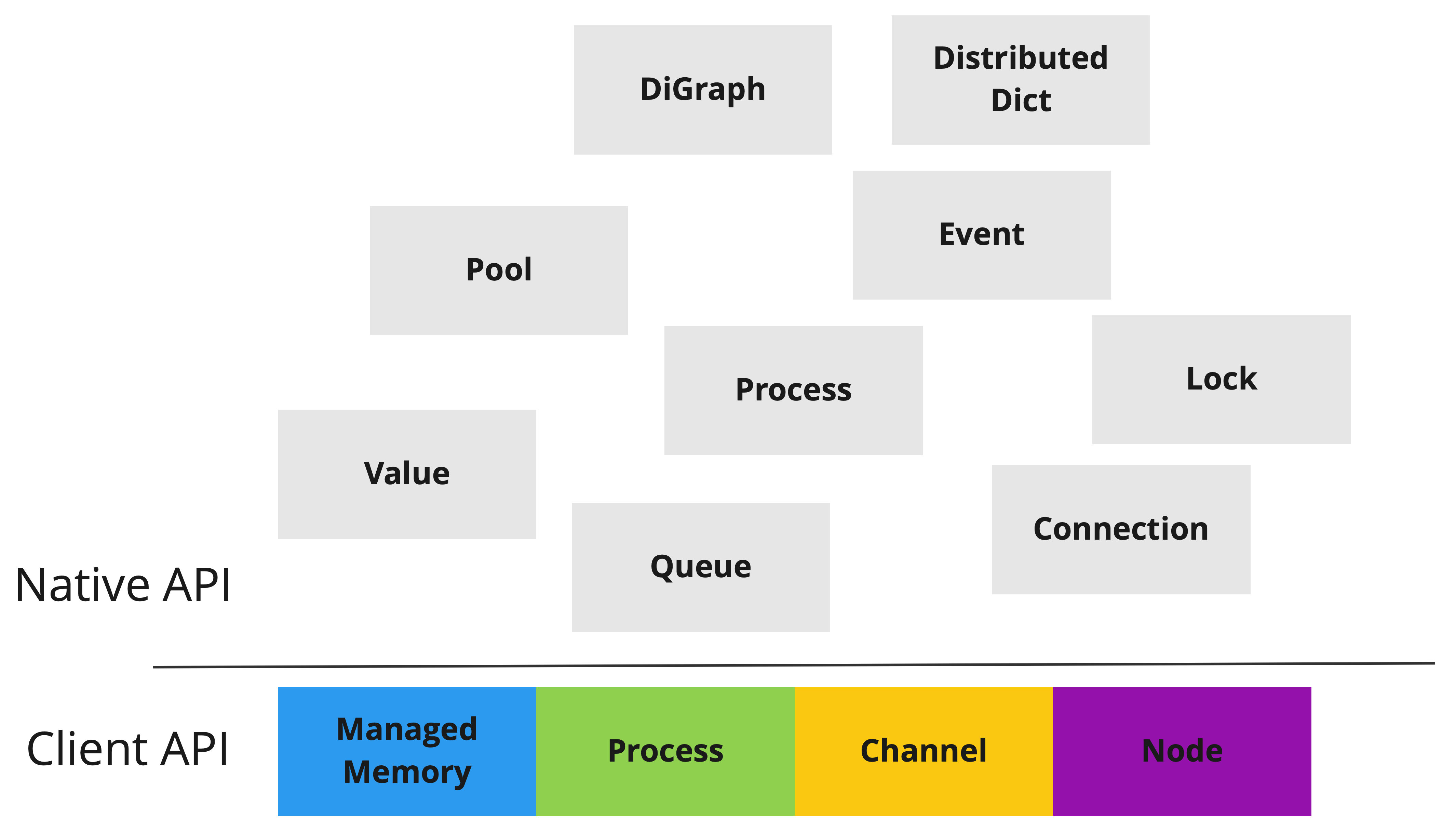
Fig. 3 A representation of the Dragon object hierarchy across Dragon Native API and Client API. Not all derived objects are shown.
All Dragon objects are built from four primary objects on top of the Dragon Client API that represent fundamental resource abstractions (see Fig. 3):
Process: A POSIX process that is tracked by the Dragon run-time services.
Memory pool: A block of shared memory managed by the Dragon run-time services that programs can allocate from.
Channel: A communications primitive used to send and receive messages managed by the Dragon run-time services
Node: A Node used by the Dragon run-time services to host resources. The abstraction mostly contains hardware information.
Derived objects use the four primary objects to provide convenient abstractions
to the programmer in the Dragon Native API. If these objects
are managed; they are identified by a unique name and ID, unmanaged objects are identified
only by their serialized descriptors. Examples of managed objects are
Queue, Lock,
Event
Python Multiprocessing with Dragon objects are always managed and refcounted. As they are based on their Dragon Native counterparts, the objects are interoperable. To this end, the Dragon Native API extends the Python Multiprocessing API into C, C++ and Fortran.
See also The API Stack.
Group of resources
A Group of resources or GSGroup is a primary resource component that includes as
its members combinations of the Dragon primary objects (processes, channels, pools, nodes).
A Global Services Client API is provided for the GSGroup object and is described
here.
Every GSGroup is described uniquely by its
GroupDescriptor. A GroupDescriptor
is an object that holds all the information needed, such as the group id, g_uid, a unique name for the group, the
state of the group, etc. These identifiers are provided by Global Services and serve to identify the Group by the
higher levels and APIs.
Members of a Group could be of the same type, such as a group of processes, or it could be a combination of different types of objects, such as a group of processes, channels, pools, etc.. A structure like this is useful for cases we need to manage a set of resources collectively. Actions like add resources to a group or remove resources from a group are provided. The user can also destroy the resources of a group as well as the group/container itself.
The GSGroup is used when we want to manage MPI jobs with Dragon.
TODO: provide a link to the MPI page.
Another example could be the case where there are MPI processes and multiprocessing processes as members of the group and we need to manage those collectively.
For now, we only support groups of processes.
Performance Costs
The API Reference for the Dragon Native API separates the calls according to how life-cycle management of an object is controlled, either managed or unmanaged. The managed and unmanaged APIs have different performance costs. Typically users should leverage all of the productivity of the managed interfaces, but they do come at the performance cost of interacting with Dragon’s services. This means there is communication and namespace management overheads for calls with “_managed_” in their signature. If a user chooses to give up automatic life-cycle management and discoverability, they can avoid these overheads with the unmanaged APIs. These users must then explicitly do life-cycle operations, such as clean-up, and any communication needed for other processes to get handles to the objects. Furthermore, users will not be able to identify objects by unique IDs or names, but only use serialized descriptors.
Policies
Much like policies may be applied to a job in a workload manager, such as Slurm, policies can be applied to objects in the Dragon resource model. Policies control many aspects of the run-time and its objects, but for now we are focusing on concepts like affinity to the caller and power consumption versus performance controls. For instance, programmers can control how a process waits for activity on an object. One or more policies can be created and applied across any/all objects in the Dragon HPC Resource model. Objects can be customized, however, at time of creation to override policy specifications.
For more information see the API reference on policies.